04 - Performance Bounds
Profiling is an effective technique to identify where your application spends most of its time. However, the next critical question is: How much optimization potential is actually available? This potential is quantified by what performance engineers call performance bounds.
Understanding Performance Bounds
In Section 2, you learned how to define benchmarks and measure various metrics, such as runtime, memory bandwidth or floating-point operations per second (FLOP/s). We can now compare those metrics with theoretical hardware capabilities to estimate simple performance bounds.
Common examples include:
- FLOP/s (Compute-bound): If your algorithm performs many arithmetic operations relative to data movement, the theoretical peak FLOP/s of the hardware provides an accurate bound.
- Memory Bandwidth (Memory-bound): Algorithms that transfer large amounts of data between memory and processors are often constrained by memory bandwidth. In such cases, peak memory bandwidth offers a realistic upper bound.
- Branch Prediction Accuracy (Control-heavy): For control-intensive applications, where frequent conditional branching significantly affects performance, the rate of correctly predicted branches indicates how much you can potentially improve execution by optimizing control flow patterns.
Daisytuner automatically estimates these performance bounds for each benchmark by comparing your measured metrics against the theoretical hardware limits of our computing cluster, daisyfield.
The Roofline Model
While single metrics help understand individual aspects of performance, a unified approach to identify bottlenecks is the Roofline Model. Roofline modeling integrates compute and memory performance metrics into a single visualization, clearly indicating which bound—compute or memory—restricts performance in your specific algorithm.
The Roofline Model plots measured performance (typically FLOP/s) against operational intensity (the ratio of computational operations to memory operations). It helps you quickly:
- Identify whether your code is compute-bound or memory-bound.
- Estimate how close your current implementation is to the theoretical peak.
- Decide which optimization strategies (e.g., increasing vectorization, reducing memory traffic) will yield the greatest benefit.
Daisytuner automatically generates Roofline models from your benchmarks and assists you in interpreting them, enabling informed optimization decisions.
Applicability
Applying Roofline analysis effectively requires analyzing at the appropriate granularity:
- Application or function-level analysis is typically too coarse. Because applications often perform many diverse operations, averaging their properties provides limited insights.
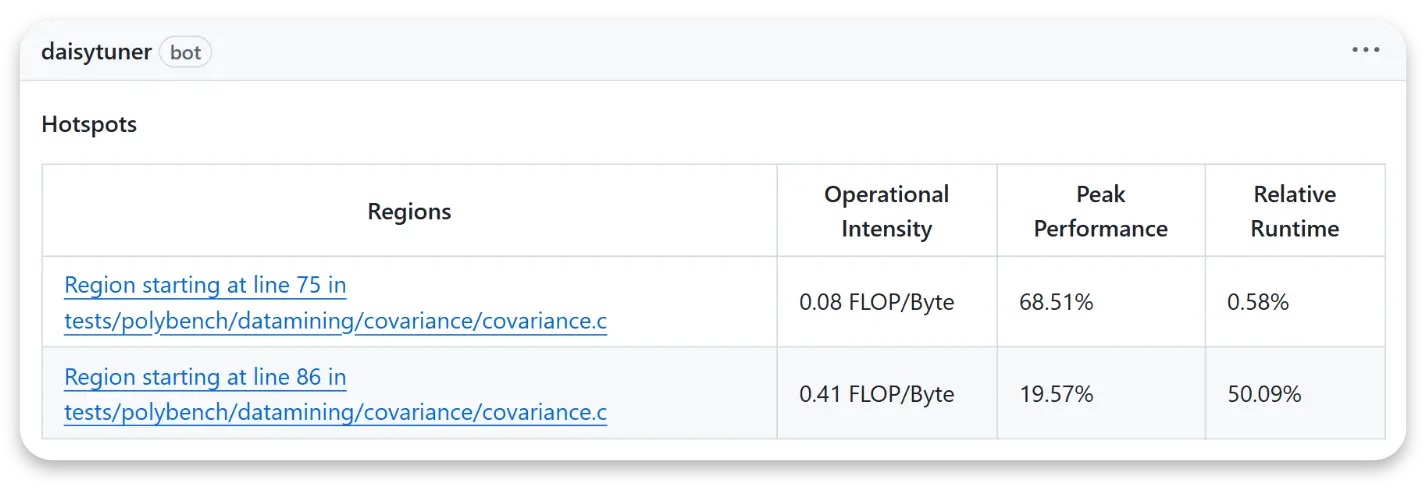
- Loop-level analysis is the most meaningful approach for Roofline analysis since it isolates the computational workloads from the rest of the application.
Automatic Loop-Level Analysis with DOCC (Experimental)
To automate and simplify accurate Roofline analysis, Daisytuner provides an experimental compiler called DOCC (Daisytuner Optimizing Compiler Collection). DOCC automatically:
- Identifies loop nests in your source code.
- Measures performance at loop-level granularity.
- Constructs precise Roofline models to help identify the correct bounds (compute or memory) affecting your loop nests.
DOCC is designed as a drop-in replacement for GCC or Clang’s C/C++ compiler. We highly recommend its use to achieve optimal and accurate performance analysis. If you’re interested in using DOCC, simply replace your existing compiler invocation with docc in your benchmark definitions.
Note: DOCC is experimental and currently supports C and C++ applications. Support for common neural network formats is under active development.
Algorithmic Limitations
Simple performance bounds can give overly optimistic estimates because they assume ideal conditions. Real-world algorithms often have inherent limitations. Consider an algorithm traversing a linked data structure via pointers:
- If the pointer-chasing pattern is an inherent property of your algorithm, memory accesses will inevitably lead to cache misses, significantly reducing achievable bandwidth compared to hardware peak.
- If the control flow of your algorithm is unpredictable, you cannot expect perfect branch prediction accuracy. Such algorithmic constraints necessitate more sophisticated performance modeling to provide accurate and realistic bounds.
We actively work on supporting advanced modeling techniques that account for algorithmic properties. If you want to learn in modeling specific algorithmic constraints, feel free to reach out to us.